|
1
|
|
|
2
|
|
|
3
|
- Kunal Agrawal
- Siddhartha Sen
|
|
4
|
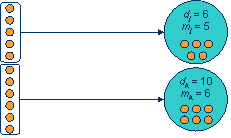
- Design and implement a dynamic processor-allocation system for adaptively
parallel jobs (jobs for which the number of processors that can be used
without waste varies during execution)
- The problem of allocating processors to adaptively parallel jobs is
called the adaptively parallel processor-allocation problem [2].
- At any given time, each job j has a desire dj and an
allotment mj
|
|
5
|
- We want to design a processor-allocation system that achieves a “fair”
and “efficient” allocation among all jobs.
- “fair” means that whenever a job receives fewer processors than it
desires, no other job receives more than one more processor than this
job received [2]
- “efficient” means that no job receives more processors than it desires
[2]
|
|
6
|
|
|
7
|
- Dynamically determine the desires of each job in the system
- Heuristics on steal rate
- Heuristics on number of visible stack frames
- Heuristics on number of threads in ready deques
- Dynamically determine the allotment for each job such that the resulting
allocation is fair and efficient
- SRLBA algorithm [2]
- Cilk macroscheduler algorithm [3]
- Lottery scheduling techniques [5]
|
|
8
|
- All jobs on the system are Cilk jobs
- Jobs can enter and leave the system and change their parallelism during
execution
- All jobs are mutually trusting (they will stay within the bound of their
allotments and communicate their desires honestly)
- Each job has at least one processor to start with
|
|
9
|
- Supercomputing Technologies Group. Cilk 5.3.2 Reference Manual. MIT Lab
for Computer Science, November 2001.
- B. Song. Scheduling adaptively parallel jobs. Master's thesis,
Massachusetts Institute of Technology, January 1998.
- R. D. Blumofe, C. E. Leiserson, and B. Song. Automatic processor
allocation for work-stealing jobs.
- C. A. Waldspurger. Lottery and Stride Scheduling: Flexible
Proportional-Share Resource Management. PhD thesis, Massachusetts
Institute of Technology, September 1995.
- C. A. Waldspurger and W. E. Weihl. Lottery scheduling: Flexible
proportional-share resource management. In Proceedings of the First
Symposium on Operating System Design and Implementation, pages 1-11.
USENIX, November 1994.
- R. D. Blumofe, C. F. Joerg, B. C. Kuszmaul, C. E. Leiserson, K. H.
Randall, and Y. Zhou. Cilk: An e±cient multithreaded runtime system. In Proceedings
of the Fifth ACM SIGPLAN Symposium on Principles and Practice of
Parallel Programming (PPoPP), pages 207-216, Santa Barbara, California,
July 1995.
|
|
10
|
- 6.895 – Theory of Parallel Systems
- Project Presentation (Proposal)
- Alexandru Caracas
|
|
11
|
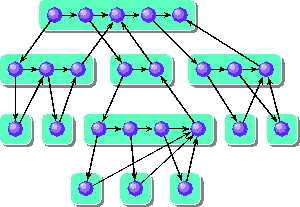
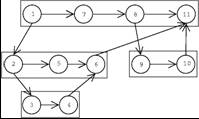
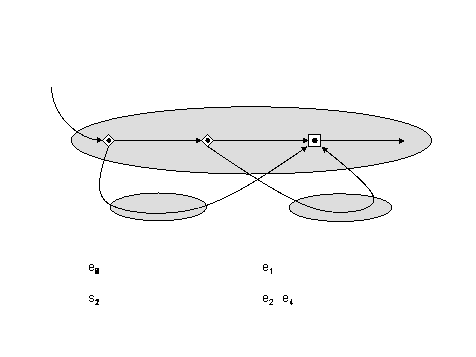
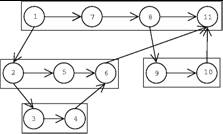
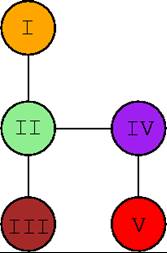
- A Cilk dag
- Numbers represent the serial execution of threads
- For example:
- Consider all threads perform file I/O operations
|
|
12
|
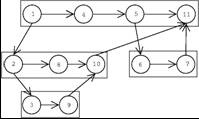
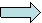
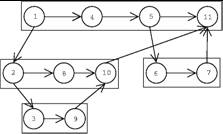
- Same Cilk dag
- Numbers represent the parallel execution of threads
- Goal:
- We would like to execute the threads in parallel while still allowing
for the serial order to be reconstructed.
|
|
13
|
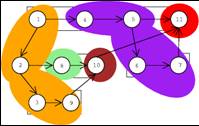
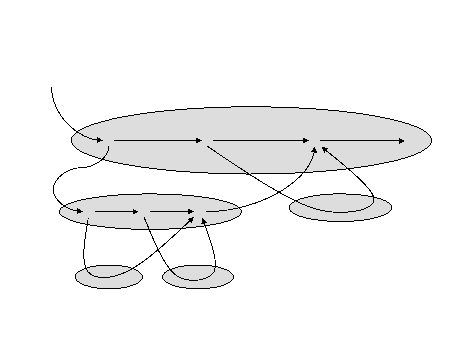
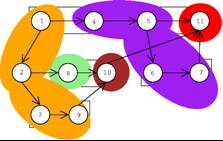
- Partitioning of the Cilk dag
- Colors represent the I/O operations done by a processor between two steal
operations.
|
|
14
|
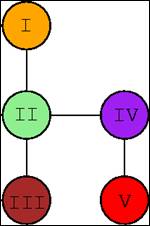
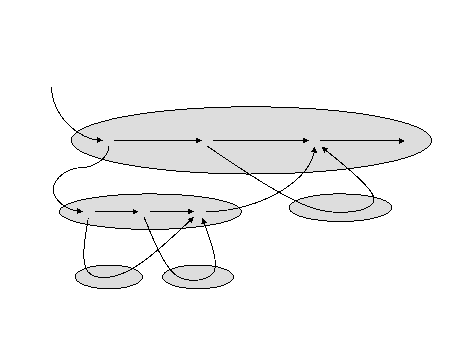
- The Serial-Append of the computation is obtained by reading the output
in the order:
- orange (I)
- green (II)
- dark-red (III)
- purple (IV)
- red (V)
|
|
15
|
- Efficient serial-append algorithm
- Analyze possible implementation:
- kernel level
- formatted file
- Cilk file system
- Implementation
- Port Cheerio to Cilk 5.4.
- Comparison with own implementation
- Port serial applications to use
serial-append (analyze their performance)
|
|
16
|
- Robert D. Blumofe and Charles E. Leiserson. Scheduling multithreaded
computations by work stealing. In Proceedings of the 35th Annual
Symposium on Foundations of Computer Science, pages 356-368, Santa Fe,
New Mexico, November 1994.
- Matthew S. DeBergalis. A parallel file I/O API for Cilk. Master's
thesis, Department of Electrical Engineering and Computer Science,
Massachusetts Institute of Technology, June 2000.
- Supercomputing Technology Group MIT Laboratory for Computer Science. Cilk
5.3.2 Reference Manual, November 2001. Available at
http://supertech.lcs.mit.edu/cilk/manual-5.3.2.pdf.
|
|
17
|
- Jason Hickey
- Tyeler Quentmeyer
|
|
18
|
- Implement a new scheduler for Cilk based on Narlikar and Blelloch’s Space-Efficient
Scheduling of Nested Parallelism paper
|
|
19
|
- Idea: minimize peak memory usage by preempting threads that try to
allocate large blocks of memory
- Algorithm: Roughly, AsyncDF runs the P left-most threads in the
computation DAG
|
|
20
|
|
|
21
|
- Cilk
- Distributed
- Run threads like a serial program until a processor runs out of work
and has to steal
- Space: p*S1
- AsyncDF
- Global
- Preempt a thread when it tries to allocate a large block of memory and
replace it with a computationally heavy thread
- Space: S1 + O(K*D*p)
|
|
22
|
- Two versions of scheduler
- Running P left-most threads does not exploit the locality of a serial
program
- Solution: Look at the cP left-most threads and “group” threads together
for locality
|
|
23
|
- Implement serial version of AsyncDF
- Experiment with algorithms to group threads for locality
- Performance comparison to Cilk
- Different values of AsyncDF’s tunable parameter
- Case studies
- Recursive matrix multiplication
- Strassen multiplication
- N-body problem
- Implement parallel version of AsyncDF
- Performance comparison to Cilk
- Additional experiments/modifications as research suggests
|
|
24
|
|
|
25
|
|
|
26
|
- Objectives :
- Design of an efficient Algorithm to convert an arbitrary NSP DAG to SP
DAG
- - Correctness preserving
- Identifying different graph topologies
- Analysis of Space and Time complexities
- Bound on increase in critical path length
- Perform empirical analysis using cilk
|
|
27
|
|
|
28
|
|
|
29
|
- Sean Lie
- sean_lie@mit.edu
- 6.895 Theory of Parallel Systems
- Wednesday October 15th, 2003
|
|
30
|
- The programmer is given the ability to define atomic regions of arbitrary
size.
- Start_Transaction;
- Flow[i] = Flow[i] – X;
- Flow[j] = Flow[j] + X;
- End_Transaction;
- With hardware support, different transactions can be executed
concurrently when there are no memory conflicts.
|
|
31
|
- Nested transactions can be handled by simply merging all inner
transactions into the outermost transaction.
|
|
32
|
- Merging transactions is simple but may decrease the program concurrency.
|
|
33
|
- Nested Concurrent Transactions (NCT):
- Allow the inner transaction to run and complete independently from the
outer transaction.
- Questions:
- When is NCT actually useful?
- How much overhead is incurred by NCT?
- How much do we gain from using NCT?
- The tool needed to get the answers:
- Transactional memory hardware simulator – UVSIM
- UVSIM currently supports merging nested transactions.
- How to get the answers:
- Identify applications where NCT is useful. Look at malloc?
- Implement necessary infrastructure to run NCTs in UVSIM.
- Evaluate performance of NCT vs. merging transactions.
|
|
34
|
- Jim Sukha
- Tushara Karunaratna
|
|
35
|
|
|
36
|
|
|
37
|
|
|
38
|
- Modify the Cilk parser to accept xbegin and xend as keywords.
- Identify all load and store operations in user code, and replace them
with calls to functions from the runtime system.
- Implement the runtime system. An
initial implementation is to divide memory into blocks and to use a hash
table to store a lock and backup values for each block.
- Experiment with different runtime implementations.
|
|
39
|
|
|
40
|
- Current Cilk: achieve atomicity using lock
- problems such as priority inversion, deadlock, etc.
- Nontrivial to code
- Transactional memory
- Software TM: overhead -> slow
- Hardware TM
|
|
41
|
- Every instruction becomes part of the a transaction
- Based on HTM
- Cilk transaction:
- cut Cilk program into atomic pieces
- Base on some language construct or compiler automatic generate
|
|
42
|
- Very different from traditional definition in Nondeterminator
- Assumption (correct parallelization)
- Definition (1st half of Kai’s master thesis)
- Efficient detection (v.s. NP-complete proved by Kai)
- Make use of current algorithms/tools
|
|
43
|
|
|
44
|
|
|
45
|
- Nondeterminator has two parts:
- Check whether threads are logically parallel
- Use shadow spaces to detect determinacy race
- SP-Bags algorithm uses LCA lookup to determine whether two threads are
parallel
- LCA lookup with disjoint-sets data structure takes O(α(v,v)) time.
- We do not care about the LCA. We just want to know if two threads are
logically parallel.
|
|
46
|
- Similar to SP-Bags algorithm with two parts:
- Check whether threads are logically parallel
- Use shadow spaces to detect determinacy race
- Use order maintenance data-structure to determine whether threads are
parallel
- Gain: Order maintenance operations are O(1) amortized time.
|
|
47
|
- Maintain two orders:
- Regular serial, depth-first, left-to right execution.
- At each spawn, follow spawn thread before continuation thread
- Right-to-left execution.
- At each spawn, follow continuation thread before spawn thread
- Claim: Two threads e1 and e2 are parallel if and
only if e1 precedes e2 in one order, and e2
precedes e1 in the other.
|
|
48
|
|
|
49
|
|
|
50
|
- Keep two pieces of state for each procedure F:
- CF is current thread in F
- SF is next sync statement in F.
- In both orders, insert new threads after current thread
- On spawn, insert continuation thread before spawn thread in one order.
Do the opposite in the other.
- On sync, advance CF to SF
- In any other thread, update shadow spaces based on current thread
|
|
51
|
|
|
52
|
|
|
53
|
- I propose Parallel Nondeterminator to:
- Check the determinacy race in the parallel execution of the program
written in the language like Cilk
- Develop efficient algorithm to decide the concurrency between threads
- Develop efficient algorithm to reduce the number of entries in access
history
|
|
54
|
- (1) Labeling Scheme
- (2) Set operation
- Thread representation (fid,
tid)
|
|
55
|
- Two sets:
- Parallel set PS(f) ={(pf, ptid) |
all threads with tid >= ptid in function pf is parallel with
the running thread of f}
- Children set CS(f)={fid | fid is the descendant of current function }
- Operations:
- Spawn: Thread Tx of function Fi spawn function Fj
- Operations on child Fj
- Operations on parent Fi
|
|
56
|
- Sync: Function Fi executes sync
- PS(Fi)=PS(Fi)-CS(Fi)
- Return: Function Fj returns to Function Fi
- CS(Fi) = CS(Fi) + CS(Fj)
- Release PS(Fj) and CS(Fj)
- Concurrency Test:
- Check if (fx, tx) is parallel with the current running thread (fc, tc):
|
|
57
|
- Serial
- read(l), write(l)
- Simplest parallel program without nested parallelism
- Two parallel read records, one write record
- Language structure like Cilk
- read: max level of parallelism, one write record
- Q: Is it possible to keep only two read records for each shared location
in Cilk Parallel Nondeterminator?
- Keep two parallel read records with highest level of LCA in parent
child spawn tree.
|
|
58
|
|
|
59
|
|
|
60
|
|
|
61
|
- 6.895 Project Proposal
- Kenneth C. Barr
|
|
62
|
- Inspiration
- UVSIM is slow
- FlexSIM is cool
- Interleave short periods of detailed simulation with long periods of
functional warmup (eg., cache and predictor updates, but not
out-of-order logic)
- Achieve high accuracy in fraction of the time
- Multi-configuration simulation is cool
- Recognize structural properties.
E.G., “contents of FA cache are subset of all larger FA caches
with same line size” so search small->large. Once we hit is small cache, we can
stop searching
- Simulate many configurations with a single run
|
|
63
|
- Combine previous ideas to speed multiprocessor simulation
- Sequential Consistency is what matters, perhaps detailed consistency
mechanisms can be interleaved with a fast, functional equivalent method
|
|
64
|
- Detailed simulation:
- P1 ld x ;null -> Sh, data sent to P1
- P2 ld x ;Sh -> Sh, data sent to P2
- P3 ld x ;Sh- > Sh data sent
to P3
- P2 st x ;Sh -> Ex, inv sent
to P1 and P3, data sent to P2
- P1 st x ;Ex -> Ex, inv sent to P2, data sent to P1
- P2 ld x ;Ex -> Sh, data sent to P2
- Shortcut
- Record access in a small “meta-directory:”
x: {P1, 0, r}, {P2, 1, r}, {P3, 2, r}, {P2, 3, w}, {P1, 4, w},
{P2, 5, r}
- All reads and writes occur in a memory; no messages sent or received,
no directory modeled, no cache model in processor (?)
- When it comes time for detailed simulation, we can reconstruct
directory by scanning backwards: x is shared by P1 and P2.
|
|
65
|
- Accesses stored in circular queue.
How many records needed for each address?
- What happens when processor writes back data, current scheme introduces
false hits.
- Does this scheme always work?
Some proofs would be nice.
|
|
66
|
- Platform
- I got Simics to boot SMP Linux
- But Bochs is open-source
- X86 is key if this is to be long-term framework
- Cilk benchmarks?
- Tasks
- Create detailed directory model
- Create meta directory
- Create a way to switch back and forth maintaining program correctness
- Measure the dramatic improvement!
|
|
67
|
- Reality
- Sounds daunting for December deadline, but if I can prove feasibility
or fatal flaws, I’d be excited
- Suggestions?
|
|
68
|
|
|
69
|
- Graph Partitioning algorithm
- Developed at University of Minnesota by George Karypis and Vipin Kumar
- Information on METIS:
- http://www-users.cs.umn.edu/~karypis/metis/
|
|
70
|
- Task: Create sequentially smaller graphs that make good representation
of original graph by collapsing connected nodes.
- Issues:
- Minor concurrency issues.
- Maintaining data locality.
- Writing large amount of data to memory in a scalable fashion.
|
|
71
|
- Task: partition small graph
- Issues: none. Runtime of this portion of algorithm very small.
|
|
72
|
- Uncoarsening and Refinement: project partition of coarsest graph to
original graph and refine partition.
- Issues:
- Major concurrency issues.
- Remaining issues under research.
|
|
73
|
- I propose to parallelize a sorting algorithm. Initially, looking at
Quick Sort, but may investigate other sorting algorithms.
- Sorting is a problem that can potentially be sped up significantly
(mergesort).
- As an alternative, considering other algorithms.
|
|
74
|
- Similar to Lab 1 approach.
- Speedy serial algorithm.
- Basic parallel algorithm.
- Runtime Analysis.
- Empirical verification of runtime analysis.
- Parallel speedups.
|
|
75
|
- Not sure about the scope of the problem.
- Anyone out there interested in this stuff?
- Other appropriate algorithms? Max-flow?
|
|
76
|
- Name: Pham Duc Minh
- Matric: HT030502H
- Email: g0300231@nus.edu.sg
- phamducm@comp.nus.edu.sg
|
|
77
|
- the discrete input signal is x(n)
- the output signal is y(n)
- the impulse response h(n)
|
|
78
|
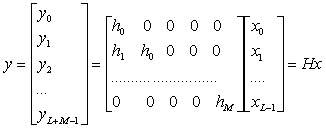
- Discrete time LTI (Linearity and Time Invariance) systems can be
classified into FIR and IIR.
- An FIR filter has impulse response h(n) that extends only over a
finite time interval, say 0≤ n ≤ M, and is identically
zero beyond that:
- {h0, h1, h2 . . . , hM, 0,
0, 0 . . .}
M is referred to as the filter order.
- The output y(n) in FIR is simplified to the finite-sum form:
- or, explicitly
|
|
79
|
- 1. Block processing
- a. Convolution
|
|
80
|
|
|
81
|
|
|
82
|
- Overlap-Add Block Convolution Method
- above methods are not feasible in infinitive or extremely long
applications
- divide the long input into contiguous non-overlapping blocks of
manageable length, say L samples
- y0 = h*x0
- y1 = h*x1
- y2 = h*x2
- Thus the resulting block y0 starts at absolute time n = 0
- block y1 starts at n = L, and so on.
- The last M samples of each output block will overlap with
- the first M outputs of the next block .
|
|
83
|
- 2. Sampling Processing
- The direct form I/O convolutional equation
- We define the internal states w1(n), w2(2), w3(n)….
- w0(n) = x(n)
- w1(n) = x(n-1) = w0(n-1)
- w2(n) = x(n-2) = w1(n-1)
- …..
- With this definition, we can y(n) in the form
|
|
84
|
- Goal of project
- Use Cilk to implement FIR filter in parallel
- Compare with the processes of DSP kit (pipeline) and the process of FPGA
(Field Programmable Gate Array) (also parallel).
|
|
85
|
- How to implement
- Multithreaded programming
- Cilk compiler
|
|
86
|
- If I finish soon, I hope additional work suggestion from staff.
|
|
87
|
|
|
88
|
- Sriram Saroop
- Advait D. Karande
|
|
89
|
- Lossless text compression scheme
|
|
90
|
- A pre-processing step for data compression
- Involves sorting of all rotations of the block of data to be compressed
- Rationale: Compressed string transforms better
- Worst case complexity of N2log(N), where N = size of block to
be sorted
- Can be improved to N(logN)2 (Sadakane ’98)
|
|
91
|
- Performance of BWT heavily dependent on cache behavior (Seward ’00)
- Avoid slowdown for large files with high degree of repetitiveness
- Especially useful in applications like bzip2 that are required to
perform well on different memory hierarchies
|
|
92
|
- Design and implementation of a cache oblivious algorithm for BWT
- Performance comparisons with standard bzip2 for available benchmarks
- Back-up: Optimizations for BWT including parallelization
|
|
93
|
|
|
94
|
|
|
95
|
- Optimal memory access
- Matrix multiply, Fast Fourier Transform
- B-trees, Priority Queues
- Concurrent?
- Lock-free?
- At least one thread can always make progress.
|
|
96
|
- Operations:
- Traverse(k) -- O(k/B)
- Insert -- O(log2n/B)
- Delete -- O(log2n/B)
- Goal:
- Design a lock-free version of the cache-oblivious algorithm
|
|
97
|
- Two algorithms
- Based on packed memory structure
- Based on alternative recursive construction and pointer-swinging
|

 Notes
Notes{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
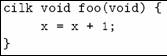{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
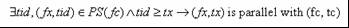{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
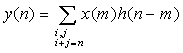{kind=link}
{kind=link}
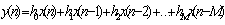{kind=link}
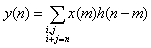{kind=link}
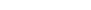{kind=link}
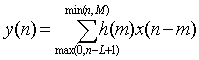{kind=link}
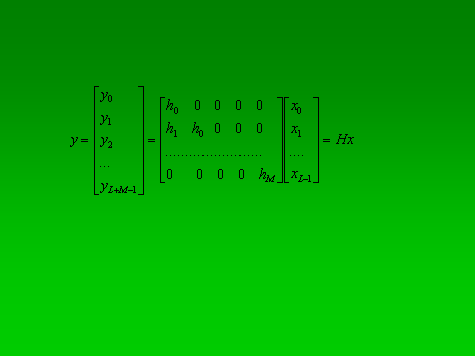{kind=link}
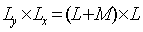{kind=link}
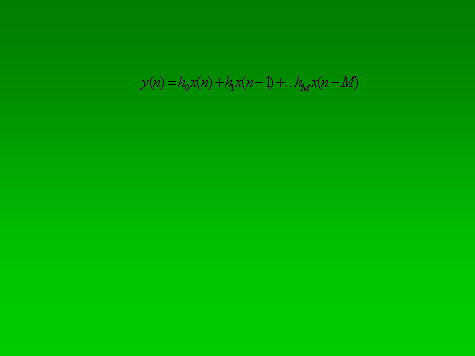{kind=link}
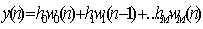{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
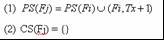{kind=link}
{kind=link}
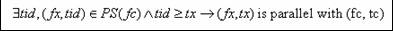{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
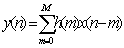{kind=link}
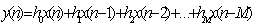{kind=link}
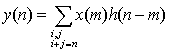{kind=link}
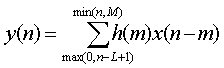{kind=link}
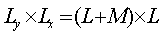{kind=link}
{kind=link}
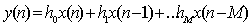{kind=link}
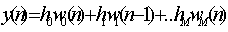{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}