The Story of a Web Connection
Abstract
The web presents a strange programming model because it forces you into writing an application that runs on two computers at once. This presents a number of challenges in application design and state management. All of these design issues, however, are ultimately influenced and built on top of the fundamental relationship that the browser has with the server.
The goal of this lesson is to fully describe that browser-server relationship. If you understand the details about how the browser makes requests to the server, you will be able to make better decisions when faced with higher-level design choices.
We will target:
- What’s a web request
- Life cycle of a web request
- Ajax and Ajax Styles
- The web security model
Introduction
Our perspective in this lesson, for the most part, is going to be the browser. There is a whole rich set of separate concerns for the server, but those begin to eek into server-side application territory.
For this lesson, we’re interested in the code that initiates web connections: be it a browser, a Javascript call, or an API request.
- Nihonbashi aside.
What, Semantically, is a Web Request
At the very basic level, an HTTP request made from the browser to the server. The reason for this request has changed over the years, and understanding that helps understand why things are the way they are today.
This isn’t a timeline, per say, as all these models are still used productively today, but they were developed this order:
- The original web, which operated like browsable set of hypertext FTP servers. Interestingly today’s Wikipedia is, in some ways, a microcosm of what the original web was: a linked, editable, text based collection of documents.
- The CGI model, where some pages were programs, and the web request was program input
- The REST model, where web applications were organized as a set of resources, and each resource had a URL that pointed to it
- The application model, where web requests are really API calls into a back-end server application
What are the parts of a web request
URL Part
PROTO://DOMAIN:PORT/PATH#FRAGMENT?PARAMS- Domain
- Path
- Port
- Fragment
- Parameters
- Protocol
Payload Part
- HTTP Verb (
GET,POST,PUT,OPTIONS, etc) POSTdata (depending…)- Cookies
- Headers * What response types you accept back, etc
These take on differet meaning depending on how you’re using the web
- If a web site is a collection of documents Then
PROTO://DOMAIN:PORT/PATHreferences a document. The HTTP verb specifies an action on that document. The rest is largely irrelevant. - If a web site is docuents + CGI scripts Then URL params, cookies, and post data represent input to those scripts. Those script, in turn, return customized documents.
- If you’re building a REST site then the path and verb are particularly important
- If a web site is an application then each request is just an API call and payload design is important.
In the document (.html) or CGI (.php) case, the path literally references a file. In the REST and application context, the path is a semantic address into your application.
What are three different ways to:
- Get a list of photos with the tag
beach - Delete a photo. (confirmation?)
- Add a photo
- Edit a photo
Do for each style. Last two styles is less of a difference, perhaps request/response type
The Life of a Web Request
W3C Navigation Timing Recommendation
An image of the process:
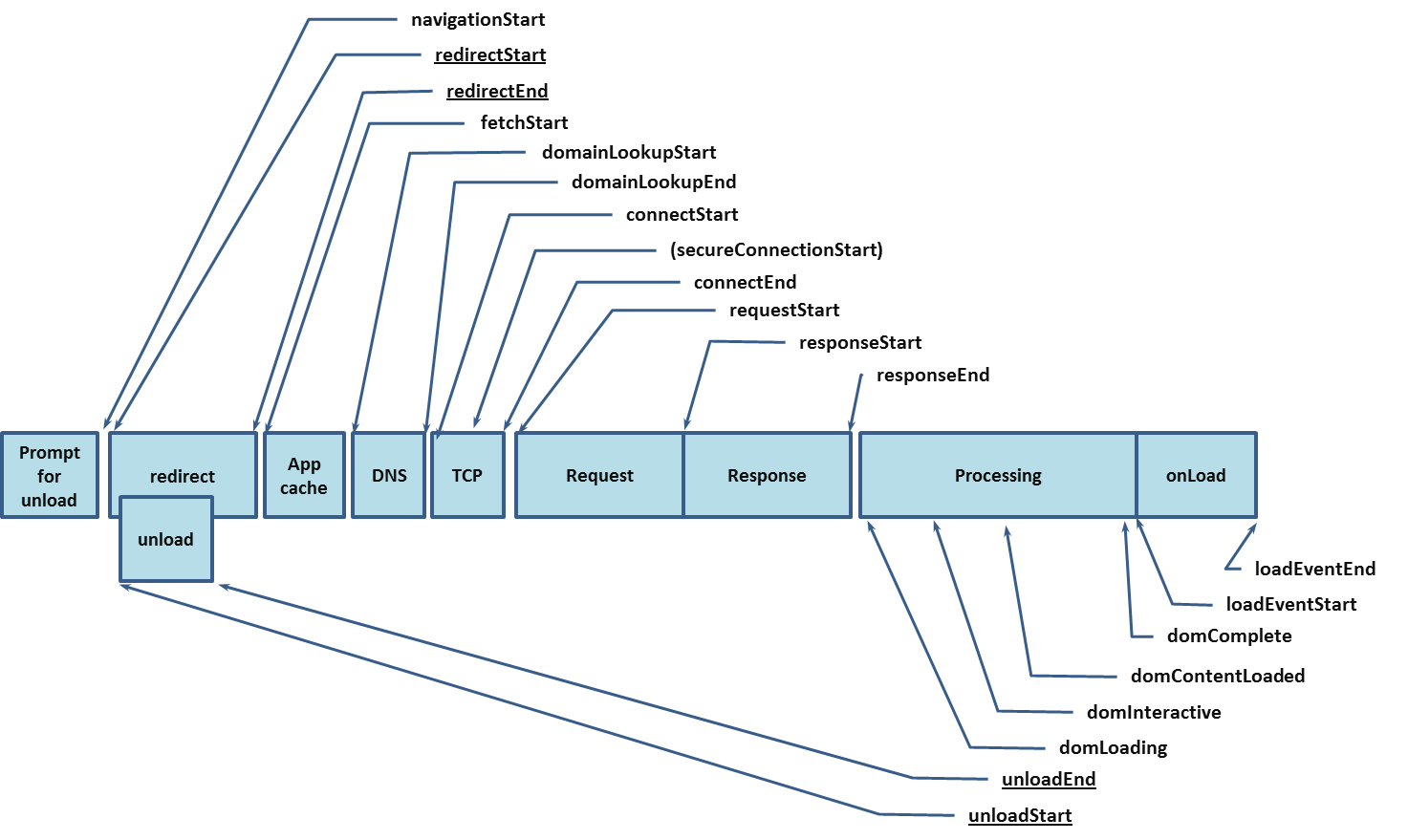
-
Before you hit the network
- Redirect
- App Cache
-
The Network
- DNS Lookup
- TCP Connect
- Request (
requestStart) - Response (
responseStart,responseEnd)
-
Processing the Response
domLoadingdomInteractivedomContentLoadeddomComplete- onLoad (
loadEventStart,loadEventEnd)
So if you’re used to the common onLoad callback of jQuery, you’re hooking in to the very end of this process.
Before you Hit the Network
The pre-network part of this lifecycle is interesting for caching and offline reasons. The browser gives you a number of mecahanisms to cache content locally, such that the network portion of this pipeline is completely skipped. With HTML5 you even have access to the cache controls from within Javascript.
Once you hit the browser
The document is scanned in linear order. Linked Javascript, scripts in the head are implemented in blocking fashion (unless in closure?) The in the body in linear fashion.
Script Ordering Demo
What order do you think the statements will output in?
In which script elements can you modify the dom?
Scripts
Life of an Ajax Requset
Ajax Styles
- UI Replacement (basically, like IFRAMEs)
- UI Updates
- Data requests
Callbacks
- Why are they used?
- How to stash state?
- Wide versus deep design
- Anonymous v. Named
Security
JSONP
First define a function that takes a JSON object
var showPictures = function(data) {
// do stuff
}Then make jsonp call
http://api.flickr.com/pictures?callback=showPicturesIt returns you a script
showPictures( data );Exercise
cross-origin-json.html
Have change pushed over Github
Cross Origin Resource Sharing (CORS)
HTML5 Rocks has a good tutorial
Headers
Access-Control-Allow-Origin: *To enable cookies over CORS, you need to set
xhr.withCredentials = true;on the client, and
Access-Control-Allow-Credentials: truein the server headers.
JS BROWSER SERVER
xhr.send() -->
preflight -------->
(if necessary)
<-------- preflight
(if necessary)
actual request --->
<--- actual response
<------------
fire onload() or onerror()A preflight looks like
OPTIONS /cors HTTP/1.1 Origin: http://api.bob.com Access-Control-Request-Method: PUT Access-Control-Request-Headers: X-Custom-Header Host: api.alice.com Accept-Language: en-US Connection: keep-alive User-Agent: Mozilla/5.0…
A preflight response looks like:
Access-Control-Allow-Origin: http://api.bob.com Access-Control-Allow-Methods: GET, POST, PUT Access-Control-Allow-Headers: X-Custom-Header Content-Type: text/html; charset=utf-8
Enabling CORS Headers
CORS demo on website
Do it on my computer. Have to rebase
Cross Site Request Forgery
- Rely on auto-login with cookies
- Construct a request to a third-party domain that amounts to a mutating API call
Defenses:
- Check the referrer header at the server-side
- Generate a token to be added on all form requests
- Short sessions
- Require the client to re-log in (or provide auth data with request) for any high-stakes state mutation
If you just adhered to good REST practice (i.e., GET request don’t have side effects), which class of clients would you fix the problem for? (passive attacks against javascript-disabled clients, e.g., you couldn’t stash a bad url in an img src. but you could still use javascript to make a post or trick the user into submitting a form.
Talk about importance of filtering for http verb on the server. Especially since a lot of server-side frameworks hide the difference between GET and POST data.
CSRF Demo
Step 1: modify code to prevent passive GET attack
Step 2: modify code to use tokens